
For a few weeks in June 2026, the smartest-seeming signal about OpenAI’s next model wasn’t coming from OpenAI. It was coming from a betting market. Traders on Polymarket had priced a GPT-5.6 launch as nearly inevitable, fueled by backend leaks and a leaked internal memo. Then, as the calendar closed in on the supposed launch window, the confidence evaporated – and OpenAI said nothing at all.
This is a story about a model that may or may not exist in shippable form. But more usefully, it’s a story about what happens to builders, marketers, and operators when the only visible evidence of a major AI release is betting odds and server logs. In that vacuum, the people who win aren’t the ones who guessed the launch date right. They’re the ones who never bet their roadmap on a guess in the first place.
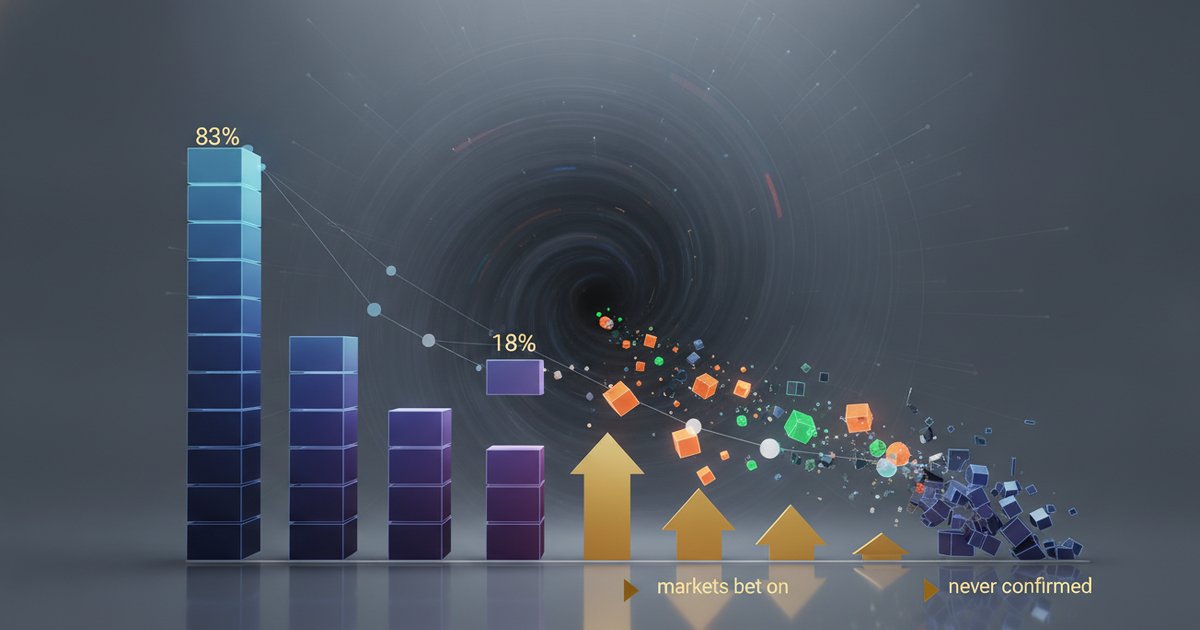
From 83% to 18%
Earlier in June, Polymarket traders gave a GPT-5.6 launch before the late-June window roughly 83% odds, with the market drawing more than $1 million in volume, according to Polymarket data reported by Yahoo Finance. That’s not idle speculation money; that’s a crowd putting real capital behind the conviction that a launch was close.
Then the window arrived – the stretch from roughly June 22 to June 28 – and the conviction collapsed. As Yahoo Finance reported in a piece bluntly titled “Traders abandon bets on a GPT-5.6 launch this week,” the odds cratered to around 18%. Traders who had been pricing in near-certainty unwound their positions as the deadline approached with no announcement.
The crucial detail: through all of this, OpenAI has not confirmed a release date, has not acknowledged a model called GPT-5.6, and has not published a model card. The market moved violently in both directions on information the company itself never validated. That asymmetry – a billion-dollar narrative built on the absence of an official word – is the whole story.

What fed the hype
So where did the 83% come from? Not from nothing. A trail of reported-but-unconfirmed signals gave the bet its initial momentum.
The first was a backend leak. According to reporting from TechTimes and AIxploria, a release candidate codenamed “kindle-alpha” allegedly surfaced briefly in Codex backend logs around June 12 before disappearing. For traders watching for any concrete sign of an imminent ship, a named release candidate appearing in production-adjacent infrastructure reads like smoke from a fire. We should be clear-eyed here: this surfacing was reported, not confirmed by OpenAI, and a codename in a log is not a launch.
The second was a memo. The same reporting points to a June 11 internal note attributed to OpenAI chief scientist Jakub Pachocki, said to describe GPT-5.6 as a meaningful improvement over GPT-5.5. If genuine, a chief scientist characterizing the model as a meaningful leap is exactly the kind of internal endorsement that makes a near-term launch feel real. Again, the memo’s specifics are unverified, and an internal assessment of a model’s quality says nothing about its release timeline.
The third was simple cadence math. GPT-5.5 shipped on April 23, 2026. A pointer release landing roughly two months later would have fit a fast, aggressive release rhythm – the kind of tempo the market had come to expect. Pattern-matching off a prior release date is seductive precisely because it feels rigorous. It isn’t. Cadence is a description of the past, not a commitment about the future.
Stack those three together – a leaked release candidate, a leaked quality memo, and a plausible cadence – and you can see how the market talked itself into 83%. Every input was real-feeling. None was official.
The information vacuum
Here is the structural problem. The entire GPT-5.6 narrative was constructed from two types of evidence: prediction-market odds and backend logs. Neither is a product announcement. Both are downstream proxies that the crowd treated as if they were the thing itself.
Prediction markets are genuinely useful for aggregating dispersed belief, but they aggregate belief, not facts. When the underlying facts are hidden – because the company is in a quiet period, or because plans are fluid, or because a release candidate got pulled for more testing – the odds don’t track reality. They track the crowd’s confidence in its own rumors. The 83%-to-18% swing wasn’t new information arriving about GPT-5.6. It was the absence of information finally being priced in as the deadline forced the question.
This is the quiet-period dynamic that trips up so many teams. Big labs go dark before launches for competitive and safety reasons. During that silence, the gap gets filled by leaks, speculation, and markets – and that fill-in material is mistaken for signal. The quieter the company, the louder the rumor mill, and the more confident the rumor mill sounds, the more dangerous it is to plan around.
Rumor-driven planning fails for a simple reason: it converts an unknowable date into a fixed assumption, and then teams build dependencies on top of that assumption. You schedule a feature launch to coincide with a model you think is dropping next week. You hold off on shipping an integration because the better model is “days away.” Then the days-away model is months away, and your roadmap is stranded on a date that never existed.
What builders should do
The corrective is unglamorous and completely within your control. In an information vacuum, you don’t try to predict the launch. You insulate yourself from needing to.
- Pin your model versions. Build against specific, documented model identifiers rather than floating aliases that can shift under you. Pinning means an unannounced backend change doesn’t silently alter your outputs, your costs, or your latency. It also means a rumored new model can’t disrupt anything you’ve shipped, because nothing you’ve shipped depends on it.
- Control your own migration calendar. Decide when you evaluate and adopt a new model based on your testing capacity and release cycle – not the vendor’s rumored ship date. When a model card actually appears, you run your evals, you compare against your pinned baseline, and you migrate on a schedule you set. The launch becomes an input to your process, not an interrupt.
- Assume nothing until there’s a model card. A codename in a Codex log is not a launch. A leaked memo praising a model is not a launch. An 83% prediction-market line is not a launch. A published model card – with documented capabilities, limits, pricing, and availability – is the first artifact you can responsibly build on. Treat everything before it as weather, not climate.
This is the practical lesson the GPT-5.6 episode hands every operator for free: in an information vacuum, pin model versions and control your migration calendar rather than planning around rumored launch dates. The teams that did this spent June shipping. The teams that planned around the 83% spent June refreshing Polymarket.
None of this is a knock on prediction markets as instruments – they did their job, which is to reflect crowd belief and then correct hard when belief met deadline. The failure mode is on the consumption side: treating a belief-aggregation tool as a release calendar. GPT-5.6 may well ship, and it may genuinely be a meaningful leap over GPT-5.5. When it does, there will be a model card, and that will be the moment to act. Until then, the most valuable position a builder can hold isn’t a bet on the date. It’s the ability to not care what the date is.